Enterprise AI costs rarely stay flat. Even when usage seems consistent, businesses start noticing response times slowing down and system performance getting unpredictable. Then add the fact that the monthly AI bill keeps climbing, and confusion and frustration set in.
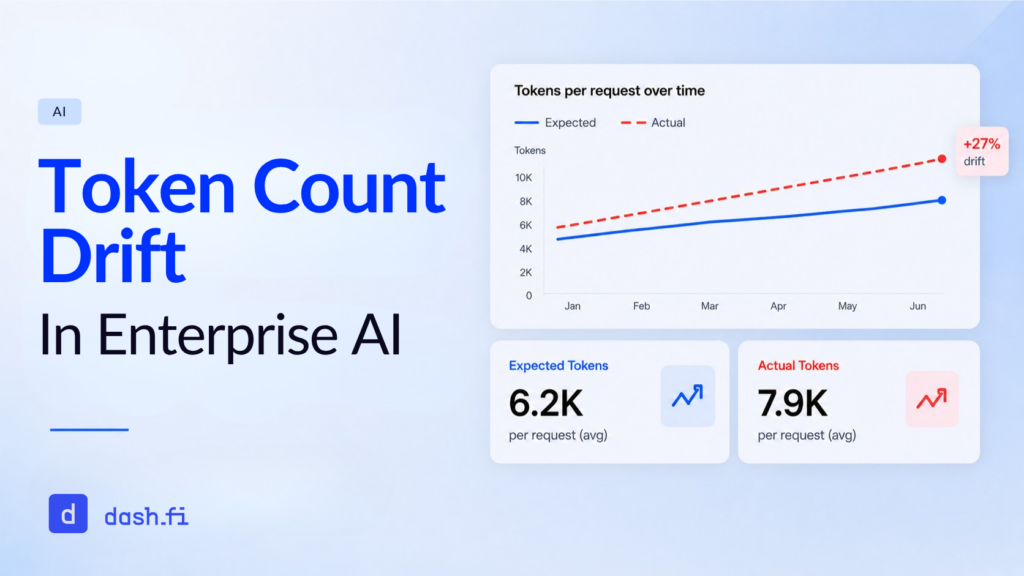
The problem is usually token count drift, a gradual increase or unexpected fluctuation in the number of tokens consumed by AI systems over time.
Token count drift is one of the most common and least understood sources of overruns in AI costs. Unlike a sudden spike in API calls, drift is subtle. It builds up quietly over time, as thousands of requests are processed, only showing up on an invoice or a latency report weeks or months later.
For businesses relying on large language models (LLMs) at scale, understanding and auditing token consumption has become a financial necessity.
What Is Token Count Drift?
Token count drift is the gradual or unexpected increase in tokens consumed per request over time, even when the underlying task or usage pattern appears unchanged. It’s different from a planned scale-up in usage as drift is an unintentional inflation.
Drift usually shows up in one of three ways:
- Gradual accumulation: Token counts per request slowly increase week over week as system prompts grow, context windows fill up, or conversation history is retained longer than intended.
- Sudden jumps: A prompt update, new feature, or configuration change causes token counts to spike unexpectedly.
- Unexplained fluctuation: Token counts vary significantly across similar requests, often due to inconsistent input formatting or dynamic prompt construction.
Token count drift directly affects three variables critical to business: cost, latency, and output quality. As token counts grow, inference costs rise proportionally, with longer inputs taking longer to process, which increases response latency.
Plus, when context windows approach their limits, model performance often degrades, which then leads to truncated outputs or reduced accuracy.
What Are the Root Causes of Token Count Drift?
It’s also helpful to understand that token drift usually comes from multiple sources at the same time. In enterprise environments, you’ll usually notice several factors accumulating over time.
1. Growing System Prompts
System prompts are the instructions passed to the model at the start of every request. As products evolve, teams tend to add to these prompts with new rules, safety guidelines, formatting instructions, and persona definitions, and while each addition is small, over several months, a system prompt that started at 200 tokens can balloon to 1,500 tokens or more. Now you’re dealing with added cost and latency with every single API call.
2. Context Window Accumulation
Many AI applications maintain conversation history so the model has context, but without a deliberate truncation strategy, this history grows with every turn. So a 10-turn conversation might consume 3x the tokens of a 3-turn conversation, even if the underlying task hasn’t changed.
3. Prompt Template Bloat
When development teams iterate on prompts by testing new instructions, adding examples, or including dynamic variables, the template can grow without anyone tracking the cumulative token impact. Each added few-shot example might add 100-300 tokens per request, multiplied across millions of API calls.
4. Unstructured or Verbose Input Data
If your AI system processes user-provided input like documents, emails, support tickets, or product descriptions, the formatting and verbosity of that input will directly affect the token consumption. Raw HTML, duplicated content, or poorly preprocessed text can dramatically inflate input token counts compared to clean, structured data.
5. Model or API Changes
When providers update models or tokenizers, the same text can produce different token counts. A model update that improves quality might also change how text is tokenized, which then results in more tokens per request and higher costs, with no change on your end.
| Root Cause | Typical Token Impact | Detection Method |
|---|---|---|
| System prompt growth | High (per-request) | Prompt versioning and token logging |
| Context accumulation | High (per-session) | Session-level token audits |
| Prompt template bloat | Medium (per-request) | Diff tracking on prompt templates |
| Verbose input data | Variable | Input preprocessing audits |
| Model/API changes | Low-Medium | Baseline testing after updates |
Token Counting in AI: How Businesses Can Track It
To genuinely get a grasp on AI cost management, businesses will need to master tracking token consumption. Most LLM APIs return token usage data in their responses, but very few businesses log and analyze this data as a systematic practice.
A structured token auditing approach should include:
- Per-request logging: Record the input and output tokens for every API call, segmented by feature, product, or team.
- Baseline benchmarking: Establish a token count baseline for each use case and then monitor for deviation from that baseline over time.
- Prompt version control: Treat prompts like code. Track changes, measure token impact, and roll back when drift occurs.
- Session-level analysis: For conversational AI, monitor how token counts evolve across a session to identify runaway context accumulation.
- Cost attribution: Map token consumption to specific features, workflows, or business units to identify the highest-cost operations.
When you proactively audit your token limits and usage patterns, you’re better positioned to control your AI costs. Auditing in this way also allows for better negotiations with providers and performance optimization. The goal here is to ensure every single token is intentional.
What’s the Difference Between a Token and a Prompt?
It’s common to mistake these two terms: token and prompt.
A prompt is the full input you send to an LLM, including everything from system instructions and conversation history to user messages and documents or data being passed in.
A token is the unit by which that prompt is measured and billed.
In practical terms: a prompt is the message, and the tokens are the characters that make up that message, but the AI models count the characters in chunks, not as individuals.
| Term | Definition | Example |
|---|---|---|
| Token | A chunk of text processed by the model (roughly 0.75 words on average) | “tokenization” = 3 tokens |
| Prompt | The full input sent to the model, including all instructions and context | System prompt + conversation history + user query |
| Context window | The maximum number of tokens a model can process in a single request (input + output) | GPT-4o: 128,000 tokens |
| Token limit | The cap on tokens per request, or a usage quota set by the API provider | Rate limits, tier caps |
How Does Token Count Drift Affect Latency and Performance?
Token consumption and latency are directly linked: Models process tokens sequentially, where more tokens mean more time to generate a response. For real-time applications like customer support chatbots, sales assistants, or internal search tools, having latency degrade from token drift can have a major impact on the user experience.
In addition to speed, token drift affects model performance in a more subtle way: as inputs approach the context window limit, the model may begin to lose track of earlier parts of the conversation or document. This is commonly referred to as the “lost in the middle” problem, where LLMs tend to recall information presented at the beginning and end of their context more reliably than content in the middle.
Runaway context accumulation can therefore degrade the quality of responses even before it hits a hard token limit.
Best Practices for Managing Token Limits and Reducing Drift
To effectively manage token count drift, you’ll need both technical discipline and a clear organizational process.
Here are the best practices for enterprise AI teams to effectively do both:
- Set and enforce context truncation policies. Define the maximum number of conversation turns or characters to include in context and summarize or drop older turns.
- Audit system prompts quarterly. Review system prompts on a regular schedule to remove redundant instructions and consolidate rules. Make sure to test whether token reductions are affecting output quality.
- Preprocess input data. Strip HTML, remove duplicates, and normalize formatting before sending data to the model, as clean inputs use significantly fewer tokens.
- Use model-appropriate formatting. JSON, markdown, and plain text tokenize differently, so test your input format and choose the one that produces the lowest token count for your use case.
- Implement token budgets. Set soft and hard limits on tokens per request at the application level and alert teams when usage exceeds thresholds.
- Monitor after every prompt change. Set your system so that any modification to a prompt template triggers a token audit before it’s deployed to production.
- Track drift metrics over time. Log average tokens per request by use case, week over week and watch for a consistent upward trend, which is a signal to investigate.
Why Token Auditing Is an Enterprise Priority
For any business running AI at scale, processing thousands or millions of API calls every month, token count drift is a cost control issue. Think of it like managing your cloud infrastructure spend or optimizing your SaaS contracts. A 20% increase in average tokens per request doesn’t just raise API costs by 20%. It also increases latency, strains rate limits, and compounds across every case simultaneously.
AI spend auditing is a rapidly emerging discipline that treats token consumption the way a finance team would treat advertising or shipping costs, as a measurable, auditable, and optimizable line item. Businesses that build token monitoring into their AI operations early will gain a lasting advantage: a better understanding of how their AI systems are actually behaving over time.
In the end, we’ve helped e-commerce companies audit their shipping contracts and advertising billing for hidden leakage. Now, AI-powered businesses have to be able to apply the same logic and rigor to auditing their token usage. Those that audit systematically will pay less, perform better, and scale more predictably.
Frequently Asked Questions
What causes token count drift in AI systems?
Token count drift is most commonly caused by:
- Growing system prompts
- Expanding conversation history without truncation
- Changes to prompt templates
- Verbose or unstructured input data
- Updates to the underlying model or tokenizer
In most cases, drift results from a combination of these factors accumulating over time without systematic monitoring.
How do I know if my AI system is experiencing token drift?
The clearest signal is a sustained increase in average tokens per request over time, without a corresponding increase in usage volume.
Do token limits vary by model?
Yes. Each model has its own context window: the maximum number of tokens it can process in a single request (input plus output combined). These limits vary wildly, from 4,000 tokens for older models to 128,000 or more for current-generation models. Token limits also apply at the API tier level, where providers may impose per-minute or per-day caps on total token consumption.
Can I reduce token count without changing my AI outputs?
Yes. Input preprocessing can significantly reduce token counts with no impact on output quality. This is the act of removing unnecessary formatting, stripping HTML, and eliminating redundant content. System prompt consolidation and context truncation policies can also reduce tokens substantially. The key is to test any reduction against quality benchmarks before deploying to production.
What is a token budget?
A token budget is the limit you set on the number of tokens allocated to a given request, session, or workflow. When you limit token budgets at the application level, you can prevent runaway context accumulation and receive early warnings when your token consumption begins to drift.


